Capítulo 7 Estimação
Nós já vimos que é possível mostrar que o preditor linear ótimo com um único regressor possui intercepto \(\alpha = \mathbb{E}[Y] - \beta*\mathbb{E}[X]\) e inclinação \(\beta = Cov(X,Y)/Var(X)\). Isso significa que, se nós considerarmos o modelo de regressão \(y_i = \alpha + \beta*x_i + e_i\), e usarmos essas fórmulas para calcular os valores de \(\alpha\) e \(\beta\) em uma população, obteríamos uma reta ajustada que é o melhor preditor linear.
Até o momento, estávamos trabalhando com a população. Porém, na prática estaremos sempre lidando com uma amostra, de forma que precisamos entender como funciona a estimação de uma regressão a partir de uma amostra.
7.1 Plug-in estimators
Se tivermos uma amostra, e não a população, é razoável pensar que uma boa estimativa para os valores populacionais de \(\alpha\) e \(\beta\) são justamente essas fórmulas, calculadas para os dados amostrais. Esse estimador dos parâmetros populacionais nós chamamos de plug-in estimates, pois sem maiores teorias, assumimos que o que vale para a população vale para a amostra. Para diferenciar as estimativas amostrais dos valores populacionais, é comum usarmos \(\hat{\beta}\) em vez de \(\beta\), ou então letras latinas \(b\) em vez das gregas \(\beta\). Vou usar letras gregas com o “chapéu”, mas outros textos utilizam letras latinas.
Ou seja, \(\hat{\beta} = \frac{\sum{(x_i - \bar{x})(y_i - \bar{y})}}{nS_x^2}\)
No caso da variância amostral de \(x\), também é comum designá-la por \(S_x^2\).
7.2 Simulando de uma Normal Bivariada
Uma distribuição de probabilidade de \(X\) e \(Y\) é Normal bivariada quando \(aX + bY\) é Normal também, para quaisquer \(a\) e \(b\). Para nós, importa aqui que \(X\) e \(Y\) são normais cada uma, e a conjunta deles também é Normal.
E diferentemente da Normal univariada, preciso representar os parâmetros por meio de vetores. A média, que antes era um escalar, agora será representada por um vetor: \(\mu = (\mu_x, \mu_y)\). Mesmo que \(\mu_x = \mu_y\), ainda assim preciso representar por um vetor. E a variância também não consegue especificar tudo que preciso saber sobre a variação nos dados. Eu preciso saber, a variância de \(X\), dada por \(\sigma_x\), a variância de \(Y\), \(\sigma_y\) e a covariância entre \(X\) e \(Y\) (que é igual a \(\mathbb{Cov}[Y,X]\)), dadas respectivamente por \(\mathbb{Cov}[X,Y]\) e \(\mathbb{Cov}[Y,X]\), que obviamente serão iguais. E nós representamos essas quatro informações por meio de uma matriz, chamada de matriz de covariância ou matriz de variância-covariância:
\[ \Sigma = \begin{bmatrix} \sigma_x^2 & \mathbb{Cov}[Y,X] \\ \mathbb{Cov}[X,Y] & \sigma_y^2 \end{bmatrix} \] Essa matriz precisa ser positiva-definida, que é uma característica de matrizes, mas que basicamente tem a ver com o fato de que não existe variância negativa e dadas as variâncias de \(X\) e \(Y\), existem limites para o que a covariância pode ser.
Como escolher os valores para essa matriz não é nada intuitivo, vamos trabalhar com a correlação, que temos uma noção melhor. Para isso, utilizaremos a seguinte relação:
\[ \Sigma = \begin{bmatrix} \sigma_x^2 & \rho \cdot \sigma_x \cdot \sigma_y \\ \rho \cdot \sigma_x\cdot \sigma_y & \sigma_y^2 \end{bmatrix} \] Ou seja, a matriz de variância-covariância pode ser parametrizada apenas em função dos desvios-padrões e da correlação entre as duas variáveis.
library(ggplot2)
library(tidyverse)
# vetor de médias
vetor_media <- c(0,0)
sigma_x <- 2
sigma_y <- 2
rho <- .6
matriz_var_cov <- matrix(c(sigma_x^2, rho*sigma_x*sigma_y, rho*sigma_x*sigma_y, sigma_y^2 ), byrow=T, nrow=2)
matriz_var_cov %>%
kable()| 4.0 | 2.4 |
| 2.4 | 4.0 |
set.seed(345)
norm_bivariada <- MASS::mvrnorm(n = 10000, mu = vetor_media, Sigma = matriz_var_cov)
bivariada_tibble1 <- as_tibble(norm_bivariada, .name_repair = "universal") %>%
rename(x = '...1',
y = '...2')
bivariada_tibble1 %>%
ggplot(aes(x)) + geom_density()
Vamos usar esses dados para fazer uma regressão.
##
## Call:
## lm(formula = y ~ x, data = bivariada_tibble1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.7942 -1.0639 -0.0067 1.0740 6.4187
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.014913 0.015907 -0.937 0.349
## x 0.588264 0.008073 72.870 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.591 on 9998 degrees of freedom
## Multiple R-squared: 0.3469, Adjusted R-squared: 0.3468
## F-statistic: 5310 on 1 and 9998 DF, p-value: < 2.2e-16A fórmula do \(\beta\) nós sabemos que depende da covariância entre as variáveis e o desvio-padrão de \(X\). Vamos então simular os dados novamente, mudando as correlações e variâncias, para entender como isso impacta a regressão a partir da fórmula da inclinação da reta.
library(ggplot2)
library(tidyverse)
# vetor de médias
vetor_media <- c(0,0)
# cov menor, dp o mesmo
sigma_x <- 2
sigma_y <- 2
rho <- .3
matriz_var_cov <- matrix(c(sigma_x^2, rho*sigma_x*sigma_y, rho*sigma_x*sigma_y, sigma_y^2 ), byrow=T, nrow=2)
matriz_var_cov %>%
kable()| 4.0 | 1.2 |
| 1.2 | 4.0 |
set.seed(345)
norm_bivariada <- MASS::mvrnorm(n = 10000, mu = vetor_media, Sigma = matriz_var_cov)
bivariada_tibble2 <- as_tibble(norm_bivariada, .name_repair = "universal") %>%
rename(x = '...1',
y = '...2')
bivariada_tibble2 %>%
ggplot(aes(x, y)) + geom_point()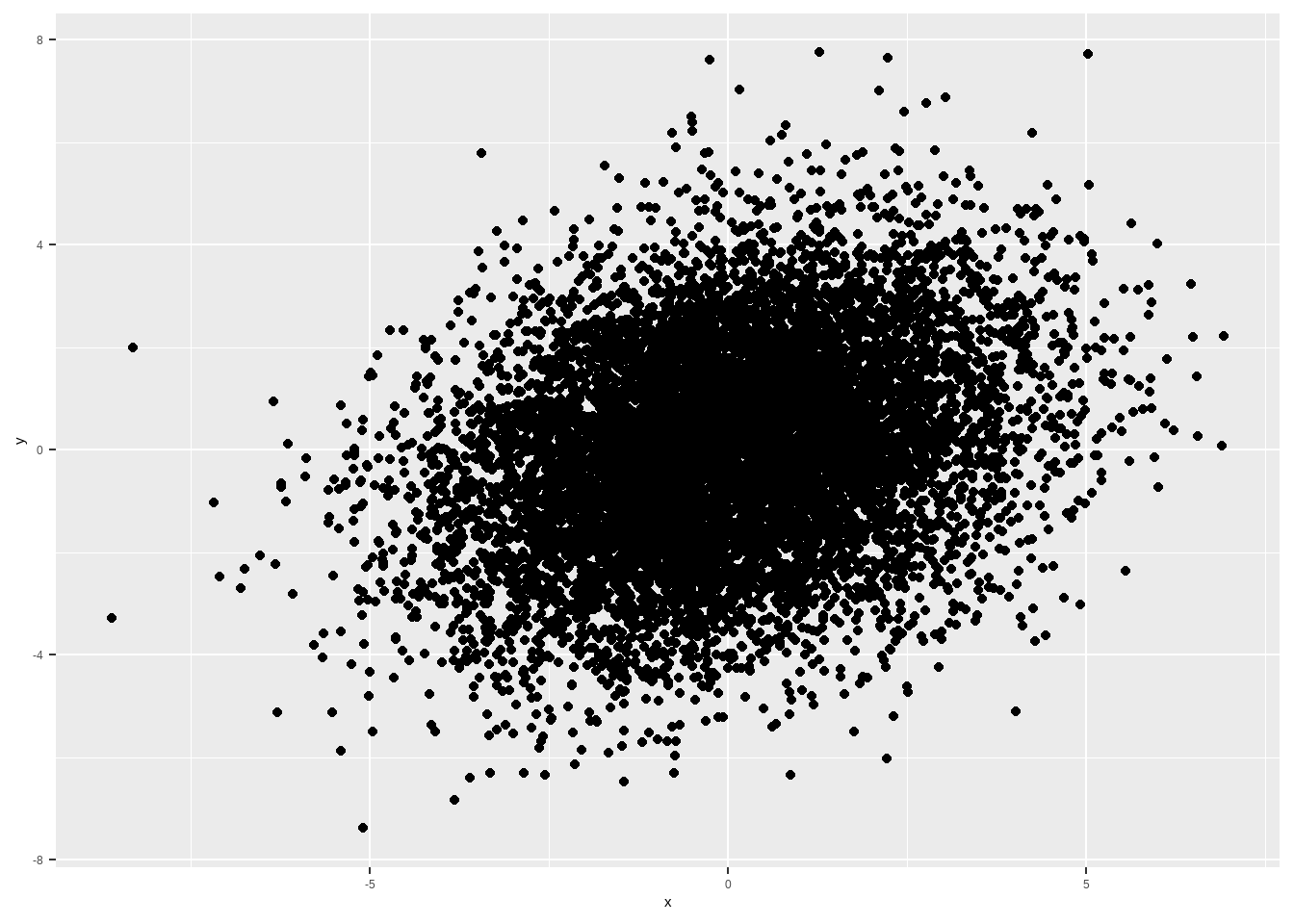
# cov igual, dp de x maior
rho <- .3
sigma_x <- 4
matriz_var_cov <- matrix(c(sigma_x^2, rho*sigma_x*sigma_y, rho*sigma_x*sigma_y, sigma_y^2 ), byrow=T, nrow=2)
matriz_var_cov %>%
kable()| 16.0 | 2.4 |
| 2.4 | 4.0 |
set.seed(345)
norm_bivariada <- MASS::mvrnorm(n = 10000, mu = vetor_media, Sigma = matriz_var_cov)
bivariada_tibble3 <- as_tibble(norm_bivariada, .name_repair = "universal") %>%
rename(x = '...1',
y = '...2')
bivariada_tibble3 %>%
ggplot(aes(x, y)) + geom_point()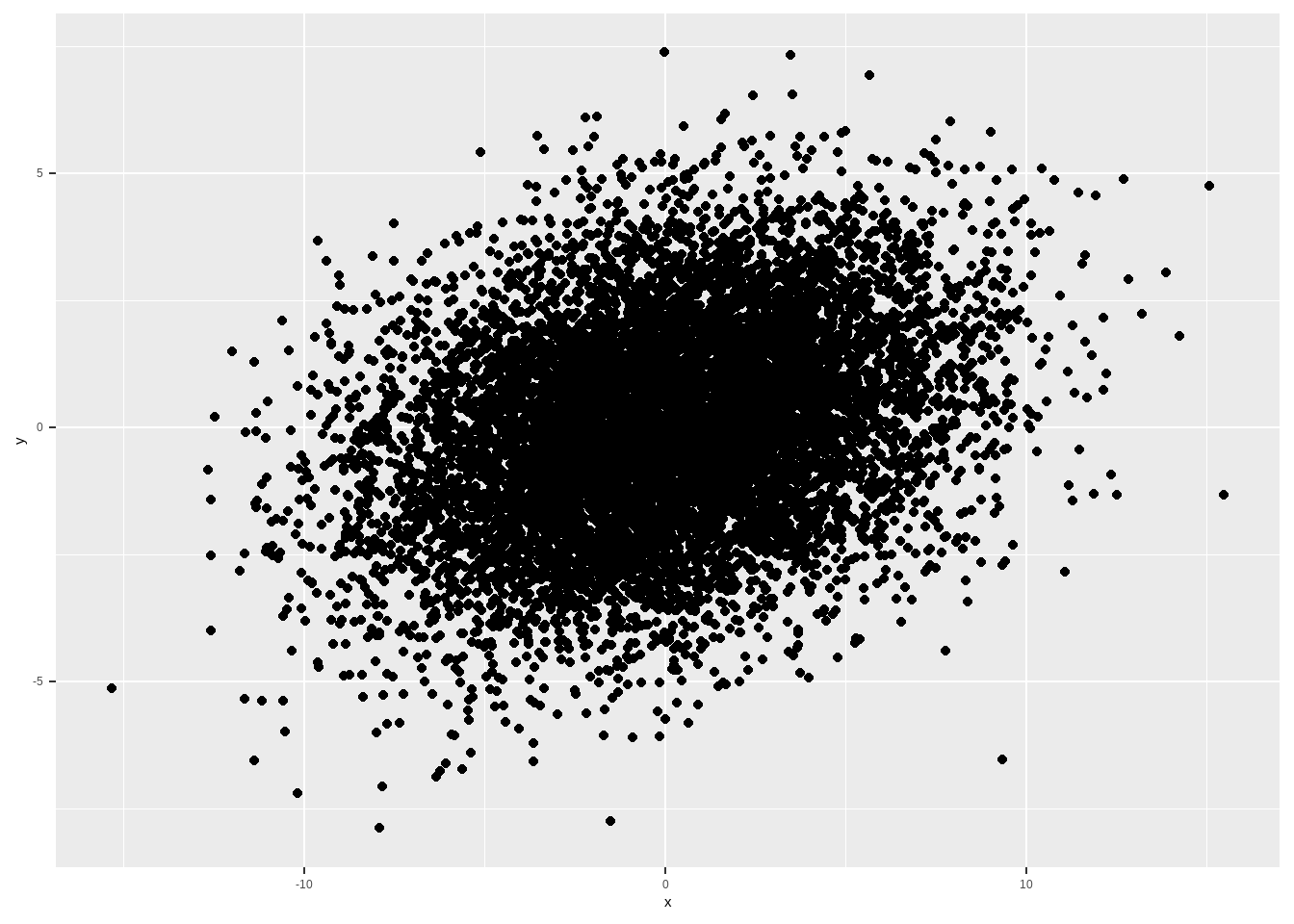
# cov menor, dp de x maior
rho <- .15
sigma_x <- 4
sigma_y <- 2
matriz_var_cov <- matrix(c(sigma_x^2, rho*sigma_x*sigma_y, rho*sigma_x*sigma_y, sigma_y^2 ), byrow=T, nrow=2)
matriz_var_cov %>%
kable()| 16.0 | 1.2 |
| 1.2 | 4.0 |
set.seed(345)
norm_bivariada <- MASS::mvrnorm(n = 10000, mu = vetor_media, Sigma = matriz_var_cov)
bivariada_tibble4 <- as_tibble(norm_bivariada, .name_repair = "universal") %>%
rename(x = '...1',
y = '...2')
bivariada_tibble4 %>%
ggplot(aes(x, y)) + geom_point()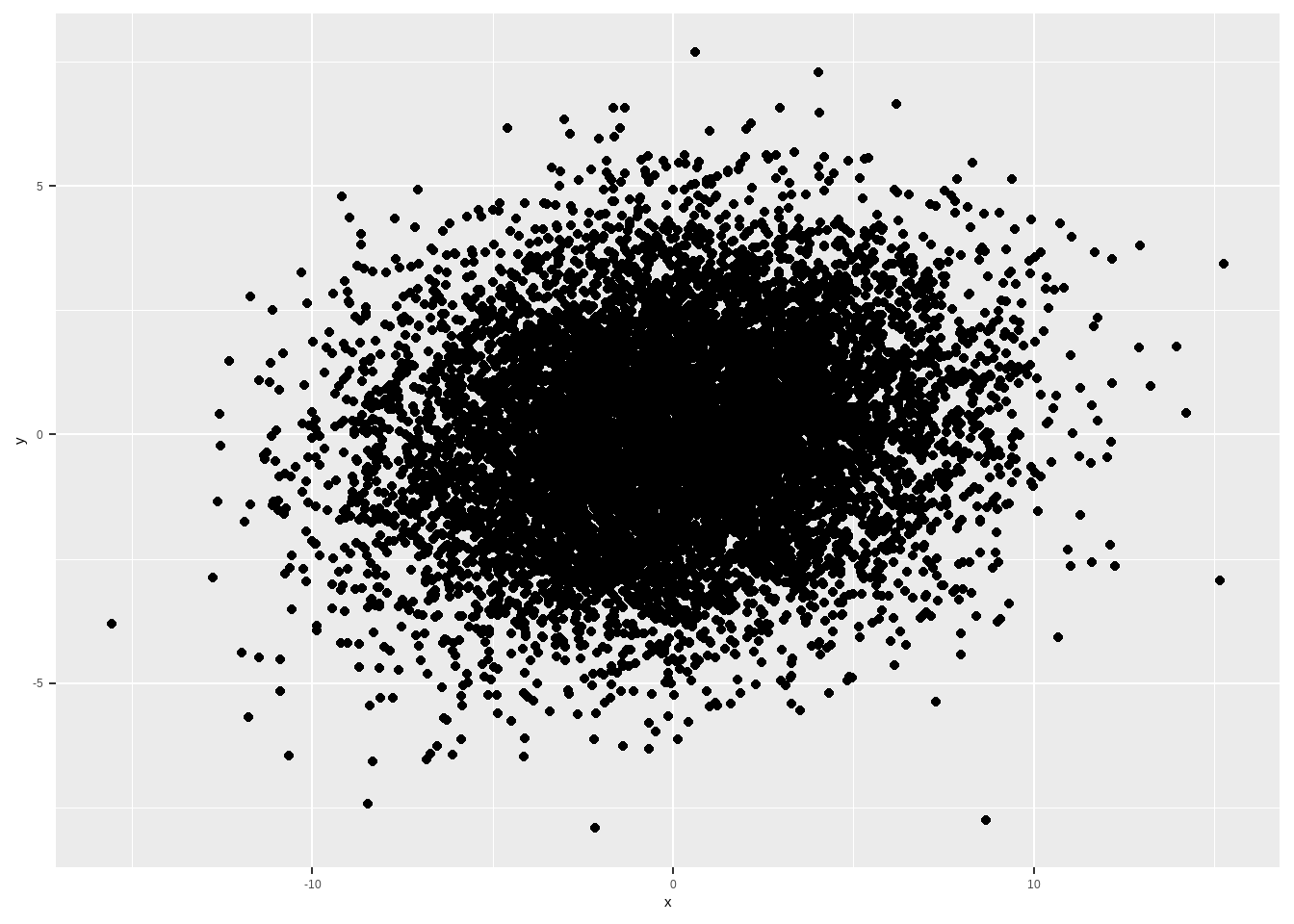
O R mostra os resultados da regressão desse jeito, e vamos aprender a interpretá-lo, mas vamos também apresentar em um formato mais amigável e, caso vocês utilizem o rmarkdown, poderão utilizar em trabalhos acadêmicos. Para isso, utilizaremos o pacote stargazer
reg2 <- lm( y ~x , data = bivariada_tibble2)
reg3 <- lm( y ~x , data = bivariada_tibble3)
reg4 <- lm( y ~x , data = bivariada_tibble4)library("stargazer")
stargazer::stargazer(list(reg1, reg2, reg3, reg4), type = "html", style = "ajps",
title = "Regressão linear", omit.stat = "f",
column.labels=c("cov = 2.4, s_x = 2", "cov = 1.2, s_x = 2", "cov = 2.4, s_x = 4", "cov = 1.2, s_x = 4" ))| y | ||||
| cov = 2.4, s= 2 | cov = 1.2, s= 2 | cov = 2.4, s= 4 | cov = 1.2, s= 4 | |
| Model 1 | Model 2 | Model 3 | Model 4 | |
| x | 0.588*** | 0.284*** | 0.148*** | 0.073*** |
| (0.008) | (0.010) | (0.005) | (0.005) | |
| Constant | -0.015 | -0.019 | 0.014 | 0.014 |
| (0.016) | (0.019) | (0.019) | (0.020) | |
| N | 10000 | 10000 | 10000 | 10000 |
| R-squared | 0.347 | 0.081 | 0.085 | 0.021 |
| Adj. R-squared | 0.347 | 0.081 | 0.085 | 0.021 |
| Residual Std. Error (df = 9998) | 1.591 | 1.892 | 1.904 | 1.974 |
| p < .01; p < .05; p < .1 | ||||
7.3 Suposições amostrais de MQO
Quando temos uma amostra, é comum supormos que os dados são independentes e identicamente distribuídos, i.i.d. Esse tipo de amostra às vezes é chamada de amostra aleatória simples. Isso é tipicamente válido em dados de corte transversal (cross-section) como uma pesquisa de opinião (survey) de intenção de voto, amostra pequena (mil, dois mil) de alunos do Brasil a partir de dados do Censo Escolar e assim por diante. O ponto é que os dados precisam ser dispersos. Se você coletar alunos de uma mesma escola, eles não tenderão a ser independentes. Se amostrar eleitores de um mesmo bairro, tampouco haverá independência. Há formas de lidar com isso, e aprenderemos mais tarde. Por enquanto, tratemos do caso mais simples.
A suposição de que dados são i.i.d significa que, em uma amostra com duas variáveis, \(X\) e \(Y\), o par \(x_i, y_i\) é independente de \(x_j, y_j\), com \(i \neq j\) e identicamente distribuídos, isto é, com a mesma distribuição. Essa suposição é importante para calcular a variância dos nossos estimadores, não para a estimativa pontual deles.
7.4 Modelo de Média amostral
Como vimos, o modelo de regressão mais simples é aquele sem preditores, em que \(Y = \mu + e\). O estimador de mínimos quadrados para \(\hat{\mu}\) é a média amostral, \(\bar{y}\). Notem que \(\mathbb{E}[Y]\) é a esperança populacional e \(\mu\) é o valor da esperança, já que a esperança do erro \(e\) é zero. Vamos então calcular a média de nosso estimador \(\bar{y}\) e sua variância.
\[ \mathbb{E}[\bar{y}] = \mathbb{E}[\sum{y_i}/n] = (1/n) \cdot \sum{\mathbb{E}[y_i]} = (1/n)\cdot \mu \cdot n = \mu \]
Portanto, o valor esperado do estimador de mínimos quadrados (a média amostral) é igual à média populacional. Quando isso acontece, isto é, quando a esperança de um estimador é igual ao parâmetro populacional dizemos que o estimador é não-viesado.
Definição 7.4. Um estimador \(\hat{\theta}\) é não-viesado quando \(\mathbb{E}[\hat{\theta}] = \theta\).
Agora, vamos calcular a variância da média amostral sob a suposição de que a amostra é i.i.d. Considerando \(y_i = \mu + e_i\), temos:
\[ \bar{y} = \sum{y_i}/n = \sum{(\mu + e_i)}/n = \sum{\mu}/n + \sum{e_i}/n = \mu + \sum{e_i}/n \]
Rearranjando, temos: \(\bar{y} - \mu = \sum{e_i}/n\)
A variância então pode ser calculada como:
\[ \mathbb{Var}[\bar{y}] = \mathbb{E}[(\bar{y} - \mu)^2] \] \[ = \mathbb{E}[( \sum\limits_{i=1}^n {e_i}/n)( \sum\limits_{j=1}^n{e_j}/n)] = (1/n^2) \sum\limits_{i=1}^n{} \sum\limits_{j=1}^n{}\mathbb{E}[e_ie_j] \] Se nós somarmos o somatório indexado no \(j\), o primeiro erro fica constante (indexado no i) e vamos passar por todo os erros de \(1\) até \(n\). Eventualmente, vamos passar por \(i\) e todos os outros diferentes de \(i\). Sabendo que os erros são i.i.d, isso significa que erros diferentes são não correlacionados e possuem esperança zero, ou seja, \(\mathbb{E}[e_ie_j] = 0, i \neq j\), e erros iguais, por serem da mesma distribuição, têm \(\mathbb{E}[e_ie_i] = \sigma^2\). Então o resultado do último somatório é uma soma de zeros, exceto para o caso em que \(i = j\), em que dá \(\sigma^2\). De forma que a equação fica:
\[ (1/n^2) \sum\limits_{i=1}^n{}\sigma^2 = (1/n^2)n\sigma^2 = \sigma^2/n \] Ou seja, a variância de nosso estimador é igual à variância populacional dividida pelo tamanho da amostra. O desvio-padrão (raiz quadrada da variância) amostral do estimador também é chamada de erro padrão.
7.5 Modelo de Regressão Linear com preditores
Tendo mostrado que o estimador do modelo com intercepto é não-viesado e calculado a variância amostral para o caso mais simples, sem preditor, vamos agora fazer o mesmo cálculo com um preditor.
Vamos assumir que o modelo de regressão linear é uma boa aproximação para CEF. Portanto, vamos supor que:
O modelo linear \(y_i = \alpha + \beta x_i + e_i\) é adequado.
\(\mathbb{E}[e|X] = 0\), isto é, o erro é não correlacionado com x.
Lembrando que a fórmula da inclinação em uma amostra é: \(\hat{\beta} = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n (x_i - \bar{x})^2}\). Pra simplificar a notação, escreveremos: \(\hat{\beta} = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{nS_x^2}\)
Vamos utilizar o fato de que \(\sum_{i=1}^n (x_i - \bar{x}) = 0\). Veja que isso é sempre verdade. Para verificar:
\[\begin{align} \sum_{i=1}^n (x_i - \bar{x})\\ &= (x_1 - \bar{x}) + (x_2 - \bar{x}) + \ldots + (x_n - \bar{x}) = \\ &= x_1 + x_2 + \ldots + x_n - n \bar{x} = \\ &= \sum_{i=1}^n x_i - n \bar{x} = \\ &= n \bar{x} - n \bar{x} = 0 \end{align}\]
Agora, vamos substituir \(y_i = \alpha + \beta x_i + e_i\) na fórmula do \(\hat{\beta}\), e depois usar \(x_i = (x_i - \bar{x}) + \bar{x}\) para obter:
\[\begin{align} \hat{\beta}\\ &= \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{nS_x^2} \\ &= \frac{\sum_{i=1}^n (x_i - \bar{x})( \alpha + \beta x_i + e_i - \bar{y})}{nS_x^2} \\ &= \frac{\sum_{i=1}^n (x_i - \bar{x})( \alpha) + \sum_{i=1}^n (x_i - \bar{x})(\beta x_i) + \sum_{i=1}^n (x_i - \bar{x})e_i + \sum_{i=1}^n -(x_i - \bar{x})\bar{y})}{nS_x^2} \\ &= \frac{\sum_{i=1}^n (x_i - \bar{x})(\beta x_i) + \sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2} \\ &= \frac{\sum_{i=1}^n (x_i - \bar{x})(\beta ((x_i - \bar{x}) + \bar{x}) ) + \sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2} \\ &= \frac{\sum_{i=1}^n (x_i - \bar{x})(\beta(x_i - \bar{x}) + \beta\bar{x}) ) + \sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2} \\ &= \frac{\beta\sum_{i=1}^n (x_i - \bar{x})^2 + \beta\bar{x}\sum_{i=1}^n (x_i - \bar{x}) + \sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2} \\ &= \frac{\beta\sum_{i=1}^n (x_i - \bar{x})^2 + \sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2} \\ &= \beta + \frac{\sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2} \end{align}\]
Agora, podemos computar a esperança condicional.
\[\begin{align} \mathbb{E}[\hat{\beta}|X]\\ &= \mathbb{E}[\beta + \frac{\sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2}|X] \\ &= \beta + \mathbb{E}[\frac{\sum_{i=1}^n (x_i - \bar{x})e_i}{nS_x^2}|X] \\ &= \beta + \sum_{i=1}^n (x_i - \bar{x})\frac{\mathbb{E}[e_i|X]}{nS_x^2} \\ &= \beta \end{align}\]
Veja que podemos usar a LIE para mostrar que a esperança não condicional de \(\hat{\beta}\) é \(\beta\).
A mesma demonstração pode ser feita com uma parametrização alternativa para o modelo de regressão linear em torno da média de \(x\). Ao final do capítulo ela é apresentada.
7.6 Variância do estimador
Podemos similarmente calcular a variância do nosso estimador, e mostrar que ela é a variância do erro dividida pela variância de \(x\) vezes o tamanho da amostra, \(n\). Vamos começar com a variância condicional ao \(X\).
\[\begin{align} \mathbb{Var}[\hat{\beta}|X]\\ &= \mathbb{Var}[\beta + \frac{n^{-1}\sum_{i=1}^n({x_i - \bar{x}})e_i}{S_x^2}|X] \\ &= \mathbb{Var}[\frac{n^{-1}\sum_{i=1}^n({x_i - \bar{x}}) e_i}{S_x^2}|X] \text{, somar uma constante não altera a variância} \\ &= \frac{1}{S_x^4}\mathbb{Var}[n^{-1}\sum_{i=1}^n({x_i - \bar{x}}) e_i|X] \text{, multiplicação por uma constante sai da variância ao quadrado} \\ \end{align}\]
É possível mostrar que dá para tirar para fora da esperança \(n^{-1}\sum_{i=1}^n({x_i - \bar{x}})\). Isso não é exatamente trivial e vou pular a derivação de que isso está certo. E se supusermos homocedasticidade, \(\mathbb{Var}[e_i|X] = \sigma^2\), então:
\[\begin{align} \frac{1}{S_x^4}\mathbb{Var}[n^{-1}\sum_{i=1}^n({x_i - \bar{x}}) e_i|X] \\ &= \frac{1}{n^2S_x^4}\sum_{i=1}^n({x_i - \bar{x})^2}\mathbb{Var}[e_i|X] \\ &= \frac{1}{nS_x^2}\mathbb{Var}[e_i|X] = \frac{\sigma^2}{nS_x^2} \text{, supondo homocedasticidade} \end{align}\]
Ou seja, a variância de nosso estimador é a variância do erro dividida pela variância de \(x\) multiplicada pelo tamanho da amostra. Isso significa que quando mais disperso o \(Y\), maior a variância do meu estimador, quanto maior a amostra, menor a variância e, por fim, quanto mais espalhado o \(X\), menor a variância do estimador.
Por fim, o erro padrão de uma estimativa é apenas o desvio padrão da variância. Portanto:
\[ se(\hat{\beta}) = \frac{\sigma}{\sqrt{nS^2_x}} \]
7.7 Estimando um modelo de regressão real
Vamos começar com um exemplo, importando dados do site Base de Dados, que possui muitas bases de dados públicas, já tratadas. Para tanto, precisaremos criar um projeto no Google cloud, conforme os passos aqui: https://basedosdados.github.io/mais/access_data_packages/
Depois, só escolher quais dos dados iremos olhar https://basedosdados.org/
Escolhi mexer com dados do censo escolar
# instalando a biblioteca
# install.packages('basedosdados')
# carregando a biblioteca na sessão
library(basedosdados)
library(bigrquery)
# para importar os dados diretamente no R, precisamos criar um id para acessar a base de dados
set_billing_id("aula-reg-manoel")
#bq_auth()
# se autenticação falhar
# importando dados
knitr::include_graphics(here("imagens", "autenticacao base dados.jpg"))
query <- "SELECT * FROM `basedosdados.br_inep_censo_escolar.escola` where sigla_uf = 'AL' and id_municipio = '2704302' and ano = 2019"
escola <- basedosdados::read_sql(query)
# query <- "SELECT count(*) as contagem, id_municipio FROM `basedosdados.br_inep_censo_escolar.escola` where sigla_uf = 'AL' and ano = 2019 group by id_municipio"
# escola <- read_sql(query)
query <- "SELECT * FROM `basedosdados.br_inep_censo_escolar.dicionario`"
dicionario <- basedosdados::read_sql(query)
query <- "SELECT * FROM `basedosdados.br_inep_censo_escolar.matricula` where sigla_uf = 'AL' and id_municipio = '2704302' and ano = 2019"
aluno <- basedosdados::read_sql(query)# dicionário de gênero e raça
# dicionario %>%
# dplyr::filter(id_tabela == "matricula", nome_coluna %in% c("sexo", "raca_cor"))
aluno_gen <- aluno %>%
dplyr::filter(regular == 1) %>%
group_by(id_escola, sexo) %>%
summarise(num_aluno_gen = n()) %>%
mutate(sexo = gsub("1", "Male", sexo),
sexo = gsub("2", "Female", sexo)) %>%
mutate(total = sum(num_aluno_gen),
percent = num_aluno_gen/total) %>%
filter(sexo == "Female") %>%
rename(percent_female = percent) %>%
dplyr::select(id_escola, percent_female)
aluno_raca <- aluno %>%
dplyr::filter(regular == 1) %>%
group_by(id_escola, raca_cor) %>%
summarise(num_aluno_raca = n()) %>%
mutate(raca_cor = gsub("1", "Branca", raca_cor),
raca_cor = gsub("2", "Preta", raca_cor),
raca_cor = gsub("3", "Parda", raca_cor)) %>%
mutate(total = sum(num_aluno_raca),
percent = num_aluno_raca/total) %>%
filter(raca_cor %in% c("Branca", "0", "Preta", "Parda")) %>%
mutate(raca_cor = gsub("0","não_declarado", raca_cor)) %>%
dplyr::select(id_escola, raca_cor, percent) %>%
pivot_wider(names_from = raca_cor , values_from = percent )
aluno_escola <- aluno_gen %>%
inner_join(aluno_raca, by = "id_escola") %>%
inner_join(escola, by = "id_escola")
aluno_escola_reg <- aluno_escola %>%
ungroup() %>%
mutate(negra = Preta + Parda) %>%
dplyr::select(negra, percent_female, tipo_localizacao, agua_potavel, esgoto_rede_publica,
lixo_servico_coleta, area_verde, biblioteca, quantidade_profissional_psicologo) %>%
filter(across(everything(), ~!is.na(.))) %>%
mutate_if(bit64::is.integer64, as.factor)
reg <- lm(negra ~ percent_female + tipo_localizacao + agua_potavel + esgoto_rede_publica + lixo_servico_coleta + area_verde + biblioteca + quantidade_profissional_psicologo, data= aluno_escola_reg)
summary(reg)##
## Call:
## lm(formula = negra ~ percent_female + tipo_localizacao + agua_potavel +
## esgoto_rede_publica + lixo_servico_coleta + area_verde +
## biblioteca + quantidade_profissional_psicologo, data = aluno_escola_reg)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.46731 -0.16217 -0.01934 0.17534 0.55176
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.070584 0.204310 0.345 0.72991
## percent_female 0.400443 0.256195 1.563 0.11880
## tipo_localizacao2 -0.251352 0.224599 -1.119 0.26373
## agua_potavel1 0.067306 0.052684 1.278 0.20212
## esgoto_rede_publica1 -0.069037 0.022951 -3.008 0.00279 **
## lixo_servico_coleta1 0.144155 0.158554 0.909 0.36378
## area_verde1 0.047138 0.025681 1.836 0.06714 .
## biblioteca1 0.009462 0.022531 0.420 0.67473
## quantidade_profissional_psicologo1 -0.069969 0.033593 -2.083 0.03787 *
## quantidade_profissional_psicologo2 -0.120828 0.092870 -1.301 0.19396
## quantidade_profissional_psicologo3 -0.306991 0.130754 -2.348 0.01935 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2222 on 418 degrees of freedom
## Multiple R-squared: 0.07237, Adjusted R-squared: 0.05017
## F-statistic: 3.261 on 10 and 418 DF, p-value: 0.00044987.8 Limitações de MQO
Os estimadores de MQO, nossos \(\hat{\beta}\) e \(\hat{\alpha}\), são não-viesados e conseguimos derivar a variância amostral deles. Porém, não há muito mais que possamos dizer sobre eles a partir apenas das suposições que fizemos, ou seja, de que o modelo linear (nos parâmetros) é adequado, e que a esperança do erro, condicional ao preditor, é zero (e assumimos, em certo momento, homocedasticidade). O que não podemos dizer a mais que gostaríamos de poder fazer?
Uma aspecto importante da inferência é, por exemplo, calcular o intervalo de confiança. Para isso, contudo, precisaremos de mais suposições do que o que fizemos até aqui. Portanto, tanto cálculos de intervalo de confiança como o p-valor e condução de testes de hipótese estão vedados com as suposições de MQO.
7.9 Distrações
Quando nós imprimimos o resultado de uma regressão no R, além dos coeficientes e o erro padrão, há uma série de outras informações apresentadas. Muitas delas são apenas distrações, mas como existem e muita gente ainda as utiliza (às vezes com bom uso), vou falar rapidamente de uma delas, o que já é possível com nosso conhecimento atual.
7.9.1 R-quadrado
Uma das estatísticas apresentadas é o chamado \(R^2\), também denominado coeficiente de determinação, que pode ser definido de várias maneiras distintas e uma delas é a razão entre a variância dos valores preditos \(\hat{Y}\) e a variância dos dados observados, \(Y\):
\[ R^2 \equiv \frac{\hat{\sigma}^2_{\hat{y}}}{\hat{\sigma}^2_y} \]
Uma definição alternativa é que o R-quadrado é a razão entre a covariância de \(y\) e \(\hat{y}\) e a variância de \(Y\): \[ R^2 \equiv \frac{\mathbb{Cov}[Y,\hat{Y}]}{\hat{\sigma}^2_y} \]
Por fim, o R-quadrado pode ser escrito como o quadrado da covariância amostral entre \(X\) e \(Y\) dividido pelo produto dos desvios-padrãos amostrais de \(X\) e \(Y\).
\[ R^2 \equiv \left(\frac{\hat{\mathbb{Cov}}[X,Y]}{\hat{\sigma}_x \cdot \hat{\sigma}_y}\right)^2 \]
Essa última parametrização é o que permite interpretar o R-quadrado como a correlação (entre \(X\) e \(Y\)) ao quadrado. É fácil ver também que uma regressão de \(X\) sobre \(Y\) gera o mesmo R-quadrado que uma regressão de \(Y\) sobre \(X\).
7.9.2 R-quadrado ajustado
O estimador \(\hat{\sigma^2}\) é viesado com relação ao parâmetro \(\sigma^2\). Então, o R-quadrado ajustado usa \(\frac{n \cdot \hat{\sigma^2}}{n-2}\) como estimador de \(\sigma^2\). Uma interpretação dada é que adicionar preditores no modelo em geral reduz a variância “não-explicada” \(\sigma^2\) (lembrem-se do “chuva na Jamaica”). E isso induz um viés da estimativa do \(R^2\), que é corrigida pelo desconto no número de preditores + 1.
7.9.3 Limites do R-quadrado
Pela primeira parametrização, é fácil ver que o \(R^2\) jamais será negativo, pois a variância é sempre não-negativa. Além disso, jamais será mais que 1, pois a variância dos valores preditos será no máximo igual à variância observada, quando as previsões forem perfeitas.
7.9.4 Para que serve?
Por muito tempo foi utilizada como uma medida do ajuste do modelo e, portanto, quanto maior o R-quadrado, melhor o modelo (ou quanto maior o R-quadrado ajustado). Hoje em dia, contudo, sabemos que é uma péssima medida de ajuste do modelo.
O modelo pode estar correto e produzir um R-quadrado pequeno, a depender da variância de \(Y\).
O modelo pode estar totalmente errado e o R-quadrado ser próximo de 1. Quando o verdadeiro modelo é não-linear e a variância de \(X\) é muito grande, isso pode acontecer se a reta de regressão ajustada não tiver \(\beta = 0\).
Há também quem use o \(R^2\) como medida de capacidade preditiva do modelo. Porém, quanto mais espalhado o \(X\), melhor o \(R^2\). A simulação abaixo mostra isso:
set.seed(123)
x1 <- rnorm(1000, 0, 10)
x2 <- rnorm(1000, 0, 2)
y1 <- 2 + 3*x1 + rnorm(1000, 0, 2)
y2 <- 2 + 3*x2 + rnorm(1000, 0, 2)
summary(lm(y1 ~x1))##
## Call:
## lm(formula = y1 ~ x1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.651 -1.279 -0.062 1.318 6.839
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.960390 0.061904 31.67 <2e-16 ***
## x1 2.996186 0.006245 479.81 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.957 on 998 degrees of freedom
## Multiple R-squared: 0.9957, Adjusted R-squared: 0.9957
## F-statistic: 2.302e+05 on 1 and 998 DF, p-value: < 2.2e-16##
## Call:
## lm(formula = y2 ~ x2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.2418 -1.2558 0.0156 1.3276 5.8205
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.98227 0.06285 31.54 <2e-16 ***
## x2 2.99309 0.03111 96.21 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.986 on 998 degrees of freedom
## Multiple R-squared: 0.9027, Adjusted R-squared: 0.9026
## F-statistic: 9256 on 1 and 998 DF, p-value: < 2.2e-16Não é possível comparar o \(R^2\) entre amostras distintas, como a simulação acima também mostra. O modelo é o mesmo, mas os dados são distintos e produzem \(R^2\) distintos.
Não faz sentido comparar o \(R^2\) entre transformações da nossa variável dependente (com e sem log, por exemplo).
Quando a amostra é a mesma e o \(y\) é o mesmo, é possível comparar modelos com o \(R^2\) e um R-quadrado maior significa um Erro Quadrático Médio menor. Mas nesse caso, é melhor usar direto o EQM.
É fácil ver, por tudo isso, que o \(R^2\) não é uma medida da “variância explicada”, com ou sem aspas. Eu não consigo entender o que é “explicar”, assim com aspas, e como é distinto de sem aspas. Portanto, melhor seria não usar e deixar de lado. Mas como é usado e os softwares mostram, tenho de perder tempo falando sobre ele para vocês.
7.10 Demonstração Alternativa que estimador é não-viesado.
Para isso, vamos usar nosso truque matemático de adicionar e subtrair Lembremos que a fórmula para o \(\hat{\beta}\) é \(\mathbb{Cov}[X,Y]/\mathbb{Var}[X]\).
Notem que: \[ \hat{\beta} = \frac{\sum({x_i - \bar{x}}) \cdot ({y_i - \bar{y}})}{\sum({x_i - \bar{x}})^2} = \frac{\sum({x_i - \bar{x}}) \cdot ({y_i - \bar{y}})}{n \cdot S^2_x} = \frac{n^{-1}\sum({x_i - \bar{x}}) \cdot ({y_i - \bar{y}})}{S^2_x} \]
Vamos então usar essa última parametrização para reescrever minha equação do \(\hat{\beta}\) e então mostrar que ele é não-viesado e calcular sua variância.
Substituindo nossa equação de regressão na fórmula, temos:
\[ \hat{\beta} = \frac{n^{-1}\sum({x_i - \bar{x}}) \cdot ({y_i - \bar{y}})}{S^2_x} = \\ \frac{\sum{(x_i - \bar{x}) \cdot y_i - (x_i - \bar{x})\bar{y}}}{n \cdot S^2_x} = \\ \frac{n^{-1}\sum({x_i - \bar{x}}) \cdot y_i - \sum({x_i -\bar{x}}) \cdot\bar{y}}{S^2_x} \]
Vamos agora usar o fato de que, para qualquer variável \(z\), a diferença média de \(z\) para a média amostral de \(\bar{z}\) é zero, isto é, \(n^{-1}\sum\limits_{i=1}^n{}z_i - \bar{z} = 0\)
Por fim, segue-se disso que, para qualquer constante \(w\) que não varia com \(i\), podemos escrever: \(n^{-1} \cdot \sum\limits_{i=1}^n{}(z_i - \bar{z})w = 0\)
Portanto, \(n^{-1} \cdot \sum({x_i -\bar{x}})\bar{y} = 0\).
Logo,
\[ \hat{\beta} = \frac{n^{-1}\sum({x_i - \bar{x}})y_i}{S^2_x} \]
Lembremos que, \(y_i = \alpha + \beta x_i + e_i\). Se eu adicionar e subtrair \(\beta\bar{x}\) da equação, não altero ela. Utilizando esse truque e rearranjando, temos o seguinte:
\[ y_i = \alpha + \beta x_i + e_i = \\ \alpha + \beta\bar{x} + \beta x_i - \beta\bar{x} + e_i = \\ \alpha + \beta\bar{x} + \beta(x_i - \bar{x}) + e_i \]
Substituindo na equação anterior, temos:
\[ \hat{\beta} = \frac{n^{-1}\sum({x_i - \bar{x}})(\alpha + \beta\bar{x} + \beta(x_i - \bar{x}) + e_i)}{S^2_x} \]
\[ \hat{\beta} = \frac{ n^{-1} \cdot (\alpha + \beta\bar{x})\sum({x_i - \bar{x}}) + n^{-1}\sum({x_i - \bar{x}}) \cdot [\beta \cdot (x_i - \bar{x}) + e_i]}{S^2_x} \]
\[ \hat{\beta} = \frac{ n^{-1} \cdot (\alpha + \beta\bar{x})\sum({x_i - \bar{x}}) + n^{-1} \beta\sum(x_i - \bar{x})^2 + n^{-1} \sum({x_i - \bar{x}})e_i} {S^2_x} \] A primeira soma é uma constante, vezes o somatório de \(x_i\) menos sua média, o que é zero. Posso então eliminar da equação, resultando em: \[ \hat{\beta} = \frac{\beta \cdot n^{-1} \cdot\sum({x_i - \bar{x}})^2 + n^{-1}\sum({x_i - \bar{x}})e_i}{S^2_x} \]
Agora, a primeira soma é a variância amostral de \(x\) multiplicada por \(\beta\). Reescrevendo a equação de outro modo, temos:
\[ \hat{\beta} = \frac{\beta \cdot S^2_x}{S^2_x} + \frac{n^{-1}\sum({x_i - \bar{x}})e_i}{S^2_x} \] Simplificando, chegamos a:
\[ \hat{\beta} = \beta + \frac{n^{-1}\sum({x_i - \bar{x}})e_i}{S^2_x} \]
Portanto, nós mostramos que o estimador \(\hat{\beta}\) pode ser decomposto no parâmetro populacional \(\beta\) mais uma soma ponderada do termo de erro. Uma vez que nossa amostra é i.i.d., sabemos que é uma média ponderada dos erros não-correlacionados. Podemos agora mostrar que o estimador é não-viesado.
Essa interpretação dos erros como uma média ponderada é útil para nós aqui por causa do seguinte. Se eu chamar meus pesos (a ponderação) de \(a_i\), posso pensar que a esperança da média ponderada de erros não-correlacionados pode ser pensada como:
\[ \mathbb{E}[ \sum{a_ie_i}] = \mathbb{E}[a_1 \cdot e_1 + a_2 \cdot e_2 + ... + a_n \cdot e_n] = a_1 \cdot \mathbb{E}[e_1] + a_2 \cdot \mathbb{E}[ e_2] + ... + a_n \cdot \mathbb{E}[ e_n] \] \[ \mathbb{E}[ \sum{a_ie_i}] = \sum{a_i} \cdot \mathbb{E}[e_i] \]
Primeiro, lembremos nossa suposição de que \(\mathbb{E}[e|X] = 0\). Isso significa que, para qualquer valor de \(x\) que eu condicionar, a esperança do erro é zero. Portanto, se a esperança do erro é sempre zero, temos:
\[ n^{-1}\sum({x_i - \bar{x}}) \cdot \mathbb{E}[e] = 0 \]
\[ \mathbb{E}[\hat{\beta}] = \beta + \mathbb{E}[ \frac{ \sum({x_i - \bar{x}})e_i}{n \cdot S^2}] = \\ \beta +\frac{\sum({x_i - \bar{x}})}{S^2_x} \cdot \mathbb{E}[e] = \beta \]